


Understanding What Makes This Nordic Paradise Special
- May 15, 2026
- blog
The allure of celebrating your union in this remarkable country extends far beyond its visual splendor. Positioned strategically between two… Read More
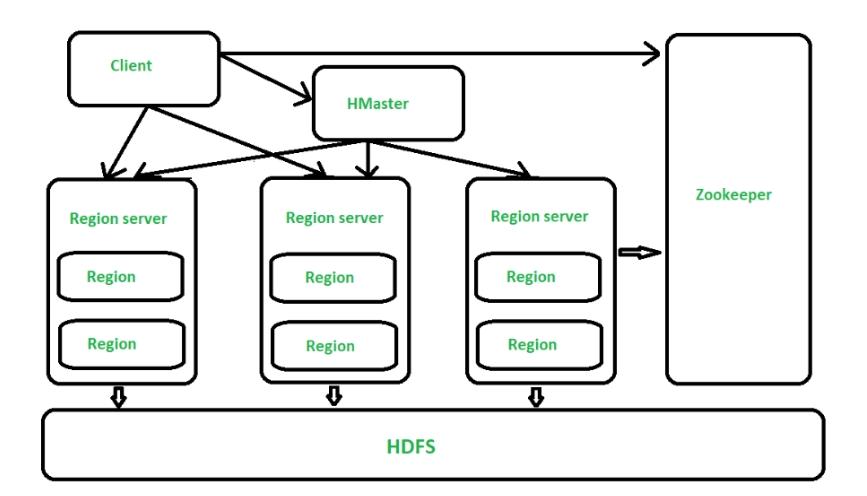
In an HBase cluster, the hmaster plays a pivotal role in managing region assignments, load balancing, and coordinating failover operations. If the HMaster experiences performance issues or becomes unavailable, the entire HBase system can become unstable, leading to significant downtime or data access issues. Proactive monitoring of the HMaster’s health is critical to avoid these disruptions, ensuring that the cluster operates smoothly and efficiently. By keeping track of HMaster’s performance, administrators can preemptively identify potential bottlenecks, failures, or performance degradation, addressing these issues before they impact the overall health of the cluster. Moreover, since HMaster is responsible for handling key administrative tasks in HBase, any problems with HMaster’s health can slow down region reassignments, affect data availability, and delay response times. Thus, monitoring tools and methodologies are essential to gain insights into how well HMaster is performing and to maintain the stability and efficiency of the entire distributed system.
Common HMaster Health Monitoring Tools and Methods
There are several reliable tools and methods available for monitoring HMaster’s health in real-time. These include JMX (Java Management Extensions), ZooKeeper status monitoring, and leveraging logs and alert systems. Each of these methods provides valuable insights into various performance aspects of HMaster, ensuring a comprehensive understanding of its health. Regular monitoring through these tools allows administrators to detect potential issues before they escalate.
Monitoring HMaster Performance with JMX
JMX (Java Management Extensions) provides a standardized way to monitor the health and performance of the HMaster. HBase exposes a variety of metrics through JMX, allowing administrators to track critical information like region assignments, load balancing, garbage collection times, and memory usage. By configuring JMX-based monitoring tools, such as Prometheus or Nagios, you can set up dashboards to visualize HMaster’s performance metrics in real-time. Additionally, these tools can be configured to trigger alerts if any key performance indicators (KPIs) reach critical thresholds.
For example, if the memory usage of the HMaster spikes or region assignments start lagging, the JMX metrics will flag these changes, giving administrators a chance to take corrective actions before these issues degrade the cluster’s overall performance. Regular monitoring through JMX can also highlight trends in HMaster’s performance over time, helping administrators optimize the system for better stability and efficiency.
Monitoring HMaster via ZooKeeper Node Status
ZooKeeper, which plays a critical role in coordinating RegionServers in HBase, can also be used to monitor the status of HMaster. ZooKeeper maintains information on whether the HMaster is running and communicates its status across the cluster. Administrators can monitor specific ZooKeeper nodes, such as the `/hbase/master` znode, which contains metadata about HMaster’s current state. If ZooKeeper detects that HMaster is unresponsive or offline, it will log this information, providing valuable insight into potential issues. For instance, if the HMaster fails, ZooKeeper can trigger failover mechanisms to promote a backup HMaster, ensuring the cluster continues to function. Monitoring ZooKeeper nodes not only allows administrators to check on HMaster’s availability but also helps in tracking cluster-wide coordination events, like region transitions and failovers, which are initiated by HMaster. This ensures the overall health and coordination of the distributed system.
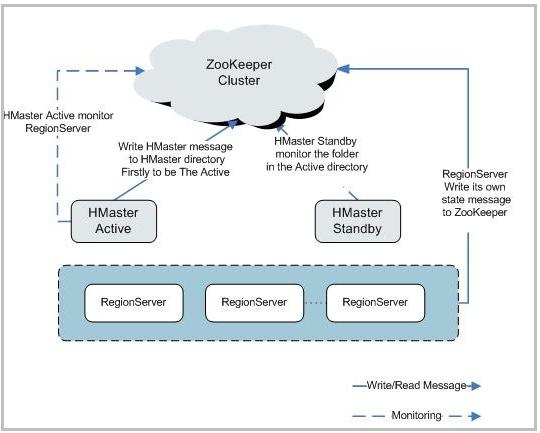
Using Logs and Alert Systems to Monitor Failures
Logs and alert systems are essential for tracking HMaster’s health and diagnosing potential issues. HBase generates detailed logs that record every action taken by the HMaster, from region assignments to garbage collection. By analyzing these logs, administrators can identify warning signs of failure, such as prolonged region assignments, failed region moves, or frequent garbage collection pauses. Moreover, setting up an alert system that monitors the HMaster logs can significantly enhance proactive issue detection. Tools like Splunk, ELK stack, or Fluentd can be used to centralize and analyze HMaster logs. Administrators can configure these tools to send real-time alerts when specific failure conditions are detected, such as frequent region server disconnections or abnormally high latency in region splits. This allows O&M teams to respond promptly and prevent small issues from escalating into critical failures.
Real-Time Monitoring of HMaster with Automation Tools
In modern environments, real-time monitoring of HMaster’s health can be automated through the use of sophisticated network monitoring tools. Tools like Prometheus, Grafana, or Datadog allow administrators to set up automated monitoring systems that continuously track HMaster’s performance. These platforms provide real-time dashboards that offer a comprehensive overview of HMaster’s health, displaying critical metrics like CPU usage, memory consumption, region assignment latency, and more. Automation tools also offer predictive analytics that can detect performance anomalies before they impact the cluster. For example, machine learning models integrated within these platforms can analyze historical data to predict when HMaster is likely to encounter resource bottlenecks. If a potential issue is detected, the tool can automatically trigger predefined remediation actions, such as redistributing regions to relieve pressure on the HMaster or restarting services to clear resource-hogging processes. In addition to performance metrics, automation tools can also be configured to monitor HMaster’s interactions with RegionServers and ZooKeeper, ensuring that the cluster remains synchronized and that HMaster’s critical tasks are completed without delay. Automation drastically reduces the manual overhead required to monitor the cluster and ensures the system remains healthy and efficient.
Conclusion
Monitoring HMaster’s health is crucial for maintaining the stability and performance of an HBase cluster. By employing a combination of tools and methods—such as JMX for real-time metrics, ZooKeeper for node status monitoring, logs for failure detection, and automation tools for continuous monitoring—administrators can ensure that the HMaster operates efficiently and avoid potential bottlenecks. Proactive health monitoring enables O&M teams to identify issues before they affect the overall system, minimizing downtime and improving the reliability of the HBase environment. Ultimately, consistent monitoring of HMaster helps to optimize performance, ensuring that the HBase cluster continues to function smoothly even under heavy workloads or complex configurations. This allows enterprises to rely on HBase as a scalable, distributed storage system capable of handling large volumes of data with high efficiency.





